
※進化型は、こっち -> OCI で、生成AI チャット 認証させて履歴保存まで
AIといえば chatgpt というか、乱立状態ですな
みなさん、お気に入りの AI が、あるようで
本当に助かる 人口脳みそ ちゃんです。
AIチャットを使うのは、WEBサイト経由で簡単に使えますよね。
でも、AIサイトの裏側を構築したり、AIに何か特別なことをさせようとすると大変ですよ
そんな大変な裏側を知ることがエンジニアとしての役目です。
ということで、nvidiaのGPUを買って、ローカルAIを構築したりして研究してました。
最初は、comfyui で、絵を描かしたり、ollama で、チャットを作ったり
基礎的なことは、やってみました。
で、Oracle Cloud でも 生成AIサービスがあるんですけど、どうやって使うのかと調べていたんですよね。
まー、WebConsoleから利用するのは、簡単に出来るんですけど、そんなもん、一般人向けサービスとしては、無理があります。
じゃーどうすんじゃーということで、OCI の SDK を使って、Webサイト経由でサービスすりゃ良いじゃん
てことで構築してみましょうね
ollamaは、AIモデルを利用する為のフレームワークみたいな物で、GUI が無いので、用意しないとダメなんですね。
で、streamlitっていうのがありまして、こいつが簡単に導入出来るし、見た目がchatgptみたくって良い感じなんですよね。
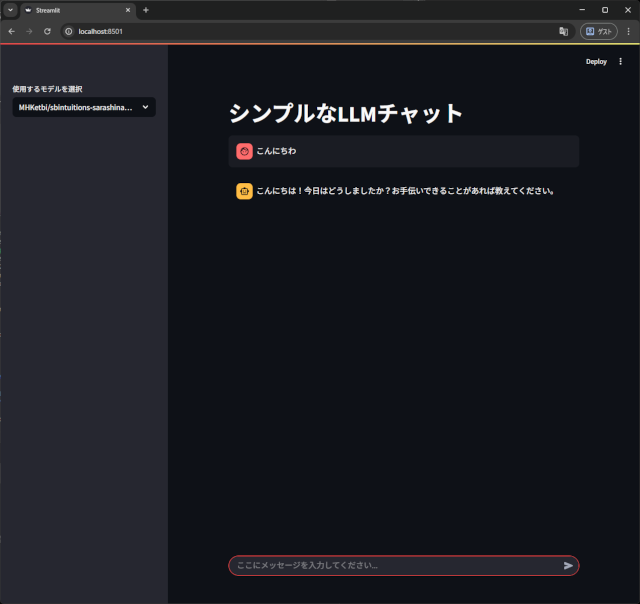
実態は、python3 で構築されていて、AIチャット部分を ollama に接続して応答させています。
で、これを OCI の生成 AI に接続すれば、良い感じのチャットが作れます。
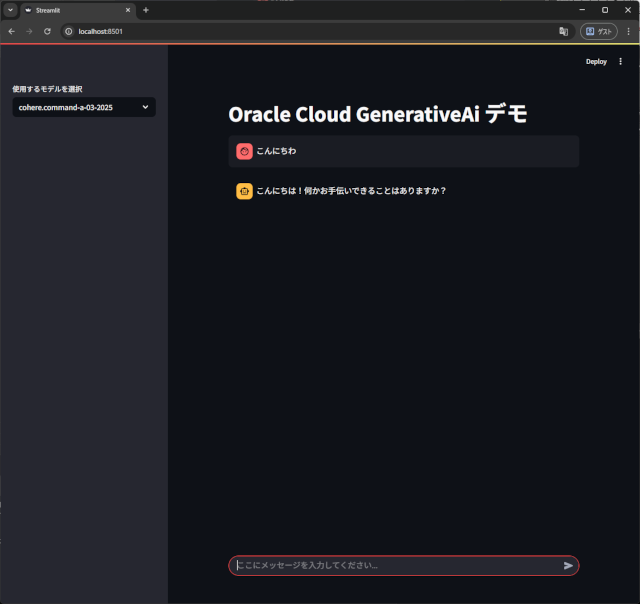
ほぼ、同じ見た目ですね。
そりゃ、ollamaで使ったソースをぱくりましたから
ちょっと、OCI版は、ollamaのAPIとは異なるので調整は必要でしたけど、簡単に修正出来ました。
当然、AIを使いましたけどね。
モデル meta.llama-3.2-90b-vision-instruct だけ、画像入力も可能ですよ
前置きが長くてすみせんね。
いよいよ、ソース公開です
chat1.py
import streamlit as st
import base64
import oci
from oci.generative_ai import GenerativeAiClient
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import (
ImageContent,
ImageUrl,
TextContent,
Message,
ChatDetails,
CohereChatRequest,
GenericChatRequest,
OnDemandServingMode
)
# OCI設定
config = oci.config.from_file("~/.oci/config", "DEFAULT")
COMPARTMENT_ID = "ocid1.compartment.oc1..aaazaaaamgunk2ogelcwqnbokeb3ureqpff4ihogepntdjkv2sagdkasusvb"
DEFAULT_MODEL = "cohere.command-latest"
max_tokens_value=3000
temperature=0.7
# 画像入力機能有無
def hasImageFunction(model:oci.generative_ai.models.Model):
if model.display_name == 'meta.llama-3.2-90b-vision-instruct':
return True
return False
client = GenerativeAiInferenceClient(config=config)
#モデル一覧
available_models = []
generative_ai_client = GenerativeAiClient(config)
ret:oci.response.Response = generative_ai_client.list_models( compartment_id=COMPARTMENT_ID)
models:oci.generative_ai.models.ModelCollection = ret.data
model:oci.generative_ai.models.Model
for model in models.items:
if model.time_on_demand_retired is None:
if "FINE_TUNE" not in model.capabilities :
if "CHAT" in model.capabilities :
available_models.append(model)
#タイトル
st.title("Oracle Cloud GenerativeAi デモ")
# モデル選択のドロップダウン(オプション)
selected_model = st.sidebar.selectbox(
"使用するモデルを選択",
available_models,
format_func = lambda model: f"{model.display_name}",
index= [i for i, model in enumerate(available_models) if model.display_name == DEFAULT_MODEL][0])
# チャット履歴の初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# チャット履歴の表示
for message in st.session_state.messages:
role = "assistant" if message.role == oci.generative_ai_inference.models.Message.ROLE_ASSISTANT else "user"
with st.chat_message(role):
for content in message.content:
if content.type == oci.generative_ai_inference.models.TextContent.TYPE_TEXT:
if role == "assistant" :
st.markdown(content.text)
else:
st.text(content.text)
if content.type == oci.generative_ai_inference.models.ImageContent.TYPE_IMAGE:
base64image = content.image_url.url.split('base64,')[1]
st.image(base64.b64decode(base64image))
hasImage = hasImageFunction(selected_model)
# ユーザー入力
prompt = None
promptattach = None
if hasImage == True:
IMAGE_FORMAT = ["png", "jpeg", "gif", "webp"]
promptattach = st.chat_input("ここにメッセージを入力してください...",accept_file="multiple", file_type=IMAGE_FORMAT)
if promptattach is not None:
prompt = promptattach.text
else:
prompt = st.chat_input("ここにメッセージを入力してください...")
if prompt is not None:
with st.chat_message("user"):
st.markdown(prompt)
if hasImage == True and promptattach is not None and len(promptattach.files) > 0:
# 画像ファイル
for file in promptattach.files:
print(f"{file.name},{file.type}")
st.image(file)
with st.chat_message("assistant"):
with st.spinner("思考中..."):
wrap_prompt = prompt + "\n----------------------------------------\n以下は、出力指定となるので、出力形式に対して応答しないで下さい。\n" + "出力形式:markdown"
chat_request = None
if selected_model.vendor == 'cohere':
#過去履歴作成
#cohere用
chat_history = []
for message in st.session_state.messages:
talken = message.content[0].text
if message.role == oci.generative_ai_inference.models.Message.ROLE_USER:
chat_history.append({"role": "USER", "message": talken})
elif message.role == oci.generative_ai_inference.models.Message.ROLE_ASSISTANT:
chat_history.append({"role": "CHATBOT", "message": talken})
#cohere用
chat_request = CohereChatRequest(
api_format= oci.generative_ai_inference.models.BaseChatRequest.API_FORMAT_COHERE,
message=wrap_prompt,
chat_history=chat_history if chat_history else None,
max_tokens=max_tokens_value,
temperature=temperature,
is_echo=True,
is_stream=False
)
else:
#汎用
chat_history = []
for message in st.session_state.messages:
# 画像は、1個までのようだ
msg = Message()
msg.role = message.role
reqcnts = []
for cnt in message.content:
if cnt.type == ImageContent.TYPE_TEXT:
reqcnts.append(cnt)
msg.content = reqcnts
chat_history.append(msg)
#新規メッセージ
contents = []
txtcontent = TextContent()
txtcontent.type = oci.generative_ai_inference.models.TextContent.TYPE_TEXT
txtcontent.text = wrap_prompt
contents.append(txtcontent)
# 画像有
if hasImage == True and promptattach is not None and len(promptattach.files) > 0:
# 画像ファイル
for file in promptattach.files:
imgcontent = ImageContent()
imgcontent.type = ImageContent.TYPE_IMAGE
base64_image = base64.b64encode(file.getvalue()).decode("utf-8")
imgcontent.image_url = ImageUrl( url = f"data:{file.type};base64,"+base64_image )
contents.append(imgcontent)
message = Message()
message.role = oci.generative_ai_inference.models.Message.ROLE_USER
message.content = contents
chat_history.append(message)
chat_request = GenericChatRequest(
api_format=oci.generative_ai_inference.models.BaseChatRequest.API_FORMAT_GENERIC,
messages=chat_history,
max_tokens=max_tokens_value,
temperature=temperature
)
#新規メッセージ チャット履歴追加
contents = []
txtcontent = TextContent()
txtcontent.type = oci.generative_ai_inference.models.TextContent.TYPE_TEXT
txtcontent.text = prompt
contents.append(txtcontent)
# 画像有
if hasImage == True and promptattach is not None and len(promptattach.files) > 0:
# 画像ファイル
for file in promptattach.files:
imgcontent = ImageContent()
imgcontent.type = ImageContent.TYPE_IMAGE
base64_image = base64.b64encode(file.getvalue()).decode("utf-8")
imgcontent.image_url = ImageUrl( url = f"data:{file.type};base64,"+base64_image )
contents.append(imgcontent)
newmessage = Message()
newmessage.role = oci.generative_ai_inference.models.Message.ROLE_USER
newmessage.content = contents
st.session_state.messages.append(newmessage)
serving_mode = OnDemandServingMode(model_id=selected_model.id)
chat_details = ChatDetails(
compartment_id=COMPARTMENT_ID,
chat_request=chat_request,
serving_mode=serving_mode
)
response:oci.response.Response = client.chat(chat_details)
result:oci.generative_ai_inference.models.ChatResult = response.data
bot_reply = ""
if selected_model.vendor == 'cohere':
#cohere用
bot_reply = result.chat_response.text
else:
#汎用
generic_response:oci.generative_ai_inference.models.generic_chat_response.GenericChatResponse = result.chat_response
chatchoice:oci.generative_ai_inference.models.ChatChoice = generic_response.choices[0]
msg:oci.generative_ai_inference.models.Message = chatchoice.message
for cnt in msg.content:
if isinstance(cnt,oci.generative_ai_inference.models.TextContent):
txt:oci.generative_ai_inference.models.TextContent = cnt
bot_reply = txt.text
else:
if isinstance(cnt,oci.generative_ai_inference.models.ImageContent):
img:oci.generative_ai_inference.models.ImageContent = cnt
bot_reply = img.image_url
if bot_reply:
# 応答 チャット履歴追加
contents = []
txtcontent = TextContent()
txtcontent.type = oci.generative_ai_inference.models.TextContent.TYPE_TEXT
txtcontent.text = bot_reply
contents.append(txtcontent)
message = Message()
message.role = oci.generative_ai_inference.models.Message.ROLE_ASSISTANT
message.content = contents
st.session_state.messages.append(message)
st.markdown(bot_reply)
COMPARTMENT_ID は、自身のに変えて下さい。
で、起動は、
streamlit run chat1.py --server.port 8501 --server.enableCORS false
です。
当然ながら、streamlit 環境と OCI SDK 環境は、構築して下さい。
Windowsだったら、WSL+Ubuntu24.04 + python3 + OCI CLI + OCI python SDK で、構築出来ますよ。



