import streamlit as st
import time
import json
import ffmpeg
import tempfile
import os
import oci
from oci.config import from_file
from oci.object_storage import ObjectStorageClient
from oci.ai_speech import AIServiceSpeechClient
from oci.ai_speech.models import CreateTranscriptionJobDetails, ObjectListInlineInputLocation, ObjectLocation, OutputLocation, TranscriptionModelDetails
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import (
ChatDetails,
CohereChatRequest,
OnDemandServingMode
)
from datetime import datetime
config = oci.config.from_file("~/.oci/config", "DEFAULT")
object_storage = ObjectStorageClient(config)
namespace = object_storage.get_namespace().data
COMPARTMENT_ID = "ocid1.compartment.oc1..aaaaaaaamgmw22hogecwqnunirb3urhoger4ihdgoilkdjkv2sabokaq5svc"
TOKENBLOCKSIZE = 2000 # トークンのブロックサイズ
config = oci.config.from_file("~/.oci/config", "DEFAULT")
# 音声情報用バケット関連
object_storage = ObjectStorageClient(config)
namespace = object_storage.get_namespace().data
bucketnm="whisper"
# AIサービス音声クライアントを作成
speech_client = AIServiceSpeechClient(config)
# Generative AIクライアントを作成
aiclient = GenerativeAiInferenceClient(config=config)
MODEL_DEF = "cohere.command-a-03-2025"
st.title('文字起こし V.3')
uploaded_file = st.file_uploader(
"音声/動画ファイルをドラッグ&ドロップまたは選択してください", type=['mp3', 'wav', 'mp4', 'm4a', 'aac', 'oga', 'wma', 'wmv', 'ogg', 'mov', '3gp', '3g2'], label_visibility="collapsed")
status_placeholder = st.empty()
# ファイルアップロード
def upload_contents_to_bucket(file_content,object_name):
try:
res:oci.response.Response = object_storage.put_object(namespace_name=namespace, bucket_name=bucketnm,
object_name=object_name, put_object_body=file_content)
if res.status == 200:
print(f"File {object_name} uploaded successfully.")
return True
else:
print(f"Failed to upload file {object_name}. Status code: {res.status}")
return False
except Exception as e:
print(f"An error occurred while uploading file {object_name}: {e}")
return False
# ファイル削除
def delete_file_from_bucket(object_name):
res:oci.response.Response = object_storage.delete_object(namespace_name=namespace, bucket_name=bucketnm, object_name=object_name)
if res.status == 204:
print(f"Object {object_name} deleted successfully.")
return True
else:
print(f"Failed to delete object {object_name}. Status code: {res.status}")
return False
# 音声からテキストへ変換
def speech2text(object_name, poolingwait=10):
start_time = datetime.now()
# ジョブ詳細定義
create_transcription_job_details : CreateTranscriptionJobDetails = CreateTranscriptionJobDetails(
compartment_id=COMPARTMENT_ID,
display_name="PythonSDKSampleTranscriptionJob",
description="Transcription job created by Python SDK",
input_location=ObjectListInlineInputLocation(
location_type="OBJECT_LIST_INLINE_INPUT_LOCATION",
object_locations=[ObjectLocation(
namespace_name=namespace,
bucket_name=bucketnm,
object_names=[object_name])]),
output_location=OutputLocation(
namespace_name=namespace, bucket_name=bucketnm),
model_details=TranscriptionModelDetails(
model_type="WHISPER_MEDIUM", language_code="ja")
)
# ジョブ作成
res:oci.response.Response = speech_client.create_transcription_job( create_transcription_job_details)
tjob : oci.ai_speech.models.TranscriptionJob = res.data
st.session_state.job_id = tjob.id
status_message = ""
try:
# ジョブ完了ホーリング
while True:
time.sleep(poolingwait)
res = speech_client.get_transcription_job(tjob.id)
tjob = res.data
current_time = datetime.now()
processing_time = current_time - start_time
processing_time_str = str(processing_time)
new_status_message = f"処理状況: {tjob.lifecycle_state} 経過時間: {processing_time_str}"
if new_status_message != status_message:
status_placeholder.write("更新中...")
time.sleep(1)
status_placeholder.empty()
status_placeholder.write(new_status_message)
status_message = new_status_message
if tjob.lifecycle_state in ["SUCCEEDED"]:
# 完了
print("Transcription job finished.")
res = speech_client.list_transcription_tasks(tjob.id)
ttasklist: oci.ai_speech.models.TranscriptionTaskCollection = res.data
tasksummary : oci.ai_speech.models.TranscriptionTaskSummary
result = []
for tasksummary in ttasklist.items:
res = speech_client.get_transcription_task(tjob.id,tasksummary.id)
ttask: oci.ai_speech.models.TranscriptionTask = res.data
outputlocation = ttask.output_location
outbucketname = outputlocation.bucket_name
outnamespace = outputlocation.namespace_name
outobjects = outputlocation.object_names
for outobject in outobjects:
print(f"Output object: {outobject} in bucket {outbucketname} namespace {outnamespace}")
res = object_storage.get_object(namespace_name=outnamespace, bucket_name=outbucketname, object_name=outobject)
responce : oci.response.Response = res
if( responce.status != 200 ):
print(f"Failed to get object {outobject}. Status code: {responce.status}")
continue
outputresut = json.load(responce.data.raw)
#結果を削除
object_storage.delete_object(namespace_name=outnamespace, bucket_name=outbucketname, object_name=outobject)
#結果出力
result.append(outputresut)
return result
else :
if tjob.lifecycle_state in ["FAILED", "CANCELING", "CANCELED"]:
# 失敗
print(f"Transcription job failed with status: {tjob.lifecycle_state}")
return None
return None
finally:
print("Transcription job ended.")
speech_client.delete_transcription_job(tjob.id)
# 音声からのテキスト変換結果を解析
def analyzetalk( textjson, blocksize=500 ):
# トークンの間を区切る
talkarray = []
rootnode = textjson[0]
if( rootnode["status"] == "SUCCESS" ) :
for node in rootnode["transcriptions"]:
lastEndTime = 0.0
resulttalk = ""
for token in node["tokens"]:
ttype = token["type"]
if ttype != "WORD":
continue
word = token["token"]
confidence = float(token["confidence"])
if( confidence < 0.1 ):
word = "?"
startTime = float(token["startTime"].rstrip("s"))
endTime = float(token["endTime"].rstrip("s"))
if( lastEndTime > 0.0 and lastEndTime < startTime ):
#間がある場合、次のトークに分ける
talkarray.append(resulttalk)
resulttalk = ""
# 次のトークンへ更新
lastEndTime = endTime
resulttalk += word
# LLMに渡すトークンに分割する
talkblocks = []
block = []
for talk in talkarray:
#現在のブロックサイズ計算
blocklength = 0
for intalk in block:
blocklength += len(intalk)
if( blocklength > blocksize ) :
# ブロックが500文字を超えたら、ブロックを保存して新しいブロックを開始
talkblocks.append(block)
block = []
# ブロックにトークを追加
block.append(talk)
# 最後のブロックを追加
if block:
talkblocks.append(block)
return talkblocks
# 結果テキストをAIで、自然言語へ変換する
def parse_talking( talkblocks ) :
talkblock = " ".join(talkblocks) # 最初のブロックを使用
msg = '''
音声から文字列に変換された結果を以下に記載しました。この文字列を自然に言葉に変換して下さい。
結果コンテンツだけでを出力し、コメントや説明は不要です。
'''
# msg = "音声から文字列に変換された結果を以下に記載しました。この文字列を自然に言葉に変換して下さい。\n"
msg += talkblock
# チャットリクエストの作成
chat_request = CohereChatRequest(
message=msg,
max_tokens=3000,
temperature=0.9,
is_echo=True,
is_stream=False
)
# サービングモードの指定(利用モデルIDを正しく指定)
serving_mode = OnDemandServingMode(
model_id=MODEL_DEF
)
# チャット詳細情報をまとめる
chat_details = ChatDetails(
compartment_id=COMPARTMENT_ID,
chat_request=chat_request,
serving_mode=serving_mode
)
# チャットAPIを呼び出す
response = aiclient.chat(chat_details)
# ここに音声からのテキスト変換結果を解析するロジックを追加
return response.data.chat_response.text
# ffmpeg 音声形式情報取得
def audiofile_info(audiofile):
try:
probe = ffmpeg.probe(audiofile)
format_info = probe['format']
duration = float(format_info['duration'])
bitrate = format_info['bit_rate']
return format_info, duration, bitrate
except ffmpeg.Error as e:
print(f"Error probing audio file: {e}")
return None, None
# ffmpeg 音声形式対応コーデックに変換
def convert_audio(input_file, output_file, codec='libopus', bitrate='64k'):
try:
(
ffmpeg
.input(input_file)
.output(output_file, vn=None, acodec=codec, audio_bitrate=bitrate)
.run(overwrite_output=True) # 既存の出力ファイルを上書き
)
print(f"'{input_file}' を '{output_file}' に変換しました。")
except ffmpeg.Error as e:
print(f"エラーが発生しました: {e.stderr.decode('utf8')}")
raise
except FileNotFoundError:
print("FFmpegがシステムPATHに見つかりません。FFmpegをインストールし、PATHを設定してください。")
raise
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
raise
if uploaded_file is not None:
status_placeholder.write("ファイルを解析しています。")
# 一時ファイルを作成してUploadedFileの内容を書き込む
temp_file_path = ""
with tempfile.NamedTemporaryFile(delete=False, suffix="whisper") as tmp_file:
with st.spinner('処理中です。しばらくお待ちください...'):
tmp_file.write(uploaded_file.read())
temp_file_path = tmp_file.name
#音声ファイル情報取得
convertfile=False
convertfilename=""
fomatinfo, duration, bitrate = audiofile_info(temp_file_path)
if( (fomatinfo['format_name'] in ["mp3","wav","ogg"]) == False ):
with st.spinner('音声ファイルへ変換中です。'):
convertfilename = temp_file_path+".ogg"
convert_audio(temp_file_path, convertfilename)
convertfile = True
##一時ファイル削除
os.remove(temp_file_path)
# 対象音声情報を決定する
if convertfile == True:
with open(convertfilename, 'rb') as f:
file_content = f.read()
os.remove(convertfilename)
else:
file_content = uploaded_file.getvalue()
status_placeholder.write("文字起こしを開始します。")
object_name = uploaded_file.name
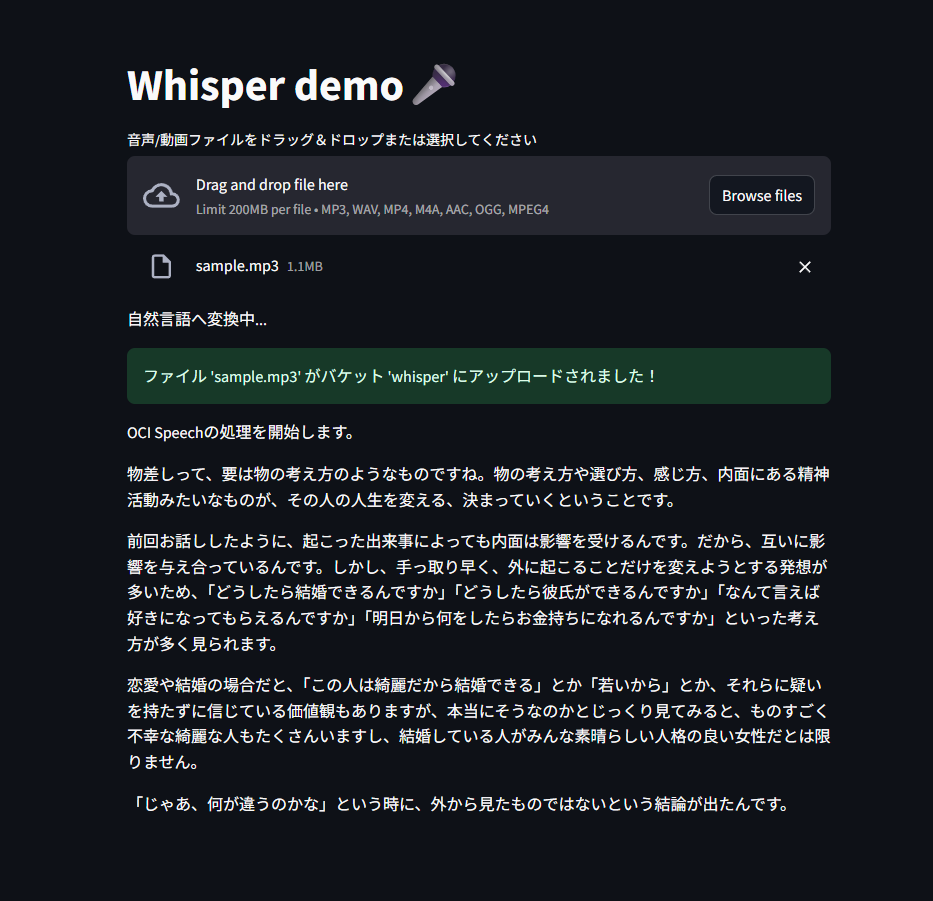
if( upload_contents_to_bucket(file_content,object_name) == False ):
st.error(f"ファイル '{object_name}' のアップロードに失敗しました。")
else:
st.session_state.uploaded_file_name = object_name
with st.spinner('処理中です。しばらくお待ちください...'):
textjson = speech2text(object_name)
delete_file_from_bucket(object_name)
if textjson is None:
# 失敗
st.error("文字起こしに失敗しました。")
status_placeholder.write("失敗しました。")
else:
talkblocks = analyzetalk(textjson, TOKENBLOCKSIZE)
status_placeholder.write("自然言語へ変換中...")
for block in talkblocks:
finalresult = parse_talking(block)
st.markdown(finalresult, unsafe_allow_html=True)
status_placeholder.empty()
# st.session_state.final_result = finalresult
st.success("文字起こしと自然言語変換が完了しました。結果を表示しています。")
else:
st.write("音声/動画ファイルをアップロードして、処理を開始してください。")